
Parcel data can be important for all types of organizations but is especially crucial for local government organizations. Due to rapid growth and development, that data is constantly changing and evolving, requiring frequent updates. Keeping this data up-to-date and available can be a challenge. For many organizations, FME desktop and FME Server play a key role in the management of this data, including the validation, updating and integration.
Most methods for updating parcel data fall into one of two strategies – Truncation or Incremental. Truncation works by deleting all records of the old data in the database and inserting a new and complete parcel dataset for each update. Incremental strategy works by finding the differences in the new dataset and only updating the records that have changed, deleting any records that have been removed and inserting new records.
In this blog, we will take a closer look at how FME can help with the second strategy: Incremental updates. We will focus mainly on the ChangeDetector transformer and configuring the writer Feature Type.
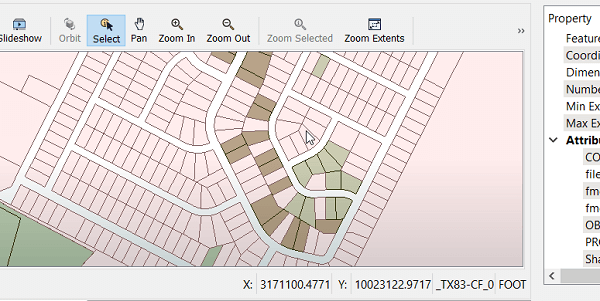
To set the stage, we are assuming that the municipality in question – Consorville – is receiving daily updates to their parcel data as a full dataset, and they need to create a process to do incremental updates – that is, only update what has changed, delete what has been removed, and add any new parcels. We will build a basic workspace that outlines the key steps to setting up your change detection process, with some tips and tricks.
1. Inspect your data
What is your source data and what is your destination data? Is there a consistent unique identifier? For this example, we are using File Geodatabase with a simple identical schema as the source and destination. Consider that you may need to add some transformers to massage the data if the format and/or structure of the source and destination are not the same.
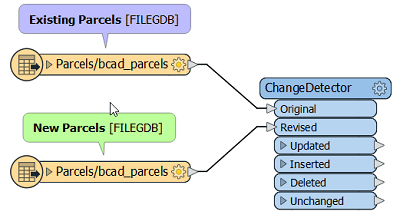
2. Connect your data to the Original and Revised data ports on the ChangeDetector transformer
Note that if your source and destination are of a different format or schema, you may need to compare your new dataset to the last source dataset instead of to your destination database. Otherwise, due to slight changes in the geometry and attribute structure, the data may show false differences.
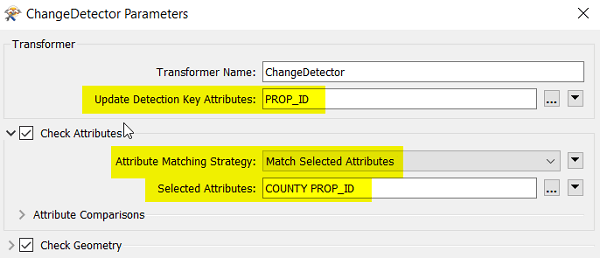
3. Set the parameters of the ChangeDetector
Specifically… the Update Detection Key Attribute, the Attribute Matching Strategy and the Selected Attributes. For the Update Detection Key, you will want to use an attribute that is consistently used as an identifier – if you use automatically-generated fields such as ESRI’s OBJECTID, you may run into problems if these change on the source data. Also, it is recommended to use the “Match Selected Attributes” as your attribute matching strategy – if you don’t, it means you will be including format attributes (hidden attributes) that are not necessary to compare and can create false differences.
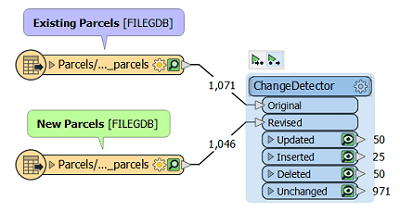
4. Run the workspace and inspect the result from each port
Is it what you expect? The best way to make sure this is working properly is to create a test dataset where you edit the data to represent any changes that might be possible. Check the result in the FME Data Inspector to make sure that the modified, added, or deleted parcels come through the correct ports on the ChangeDetector.
This table explains the test data used for this workspace.
| Modification Type | Example | Transformer Port |
| Geometry Modification | Change shape of existing lot | Updated |
| Attribute content modification | Change attribute value for COUNTY | Updated |
| Delete record | Remove lot | Deleted |
| Add record | Add new lot with new PROP_ID | Inserted |
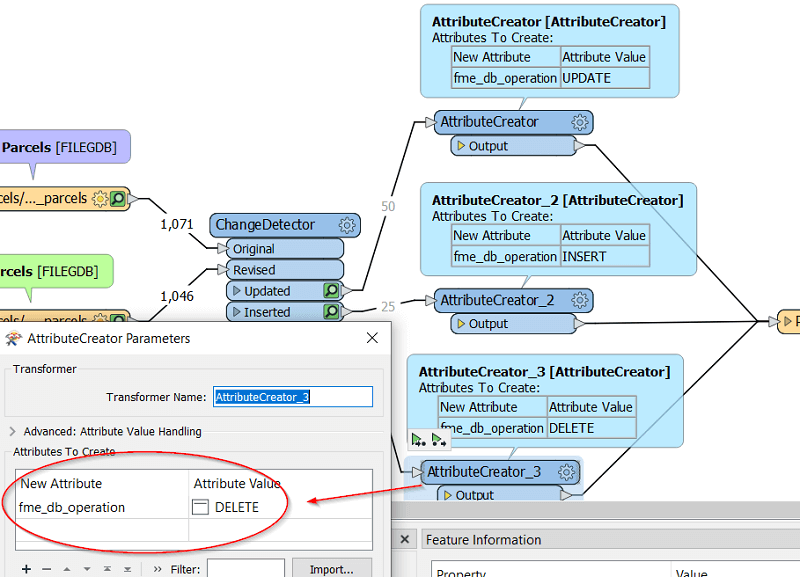
5. Make the changes to your database
There are multiple ways to do this, but one easy way to do it is to use one Writer Feature Type to write to your parcel database, and modify the attribute “fme_db_operation” according to the operation you would like to do. The options are “UPDATE”, “INSERT” and “DELETE”. We can use an AttributeCreator to set this attribute, and then connect to the Writer Feature Type.
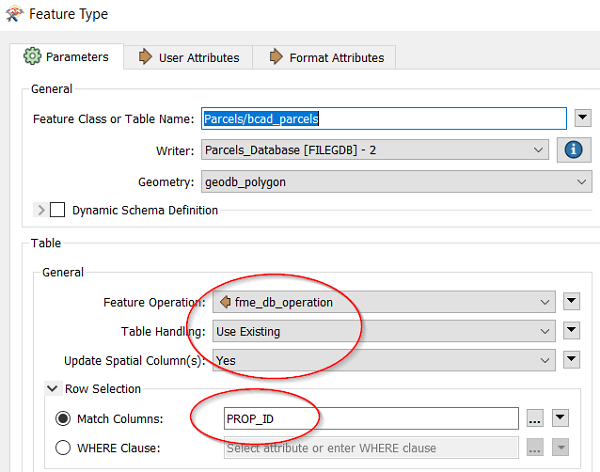
6. Configure your Writer Feature Type to make the database changes according to the attribute “fme_db_operation” and list your consistent ID as the Match Column.
This will make sure that when each object reaches the writer, the correct operation will be done, whether it is an update, insert or delete.
7. Run your Workspace
You’re done! Don’t forget to test well and check the log to make sure that everything ran smoothly!
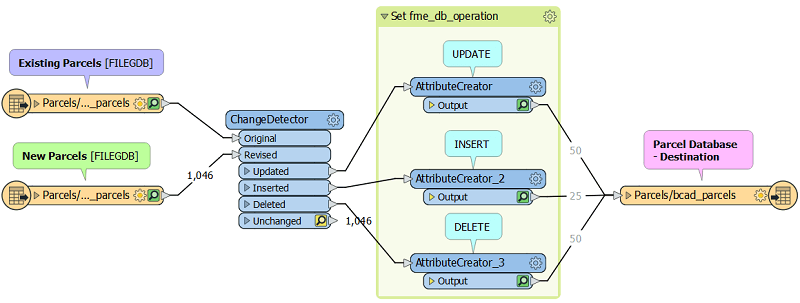
This is an example of a very simple workspace that allows you to update your parcels database incrementally. To fully implement this into your business processes, you might want to include some of the following optimization:
- Reporting
- Archiving modified or removed parcels
- Error trapping (in case there is faulty data)
- Automation (for example, setting it up to run nightly with the correct new datasets, e-mail notifications, etc.)
Parcel data is critical for many local government organizations and it is important to maintain for tax purposes and to ensure that quality, up-to-date data is available for decision-making and providing quality services to citizens.
There are two main methods for updating parcel data: Truncation and Incremental. While this blog described some key steps to the incremental method, each strategy has its pros and cons, and can be optimized for different scenarios depending on the business processes of the organization.
Do you have questions about which parcel update strategy is best for your organization?