
-
Are you processing high volumes of data in a single FME workspace?
-
Are your FME workspaces taking too much time to complete?
-
Are your FME workspaces consuming too much memory, to the point of sporadic system failure?
If you’ve answered yes to any of these questions, we suggest chaining workspaces!
What is Workspace Chaining?
Instead of processing the entirety of your data in one single job, a workspace chaining logic allows you to parse your input data and process it in several different jobs.
While only some data structures are conducive to workspace chaining, this method can significantly improve the performance of your FME workspace whenever your data allows for it. If a workspace reads multiple database tables, files, or multiple layers within a single file, you can chain your workspace by processing each element separately.
How Workspace Chaining Works
The most commonly-used chaining method is the Master/Child workspace logic. In this case, the Master workspace typically acts as an orchestrator by generating a number of triggers, each of which includes a specific set of parameters to be sent to the Child workspace. Then, instead of handling the data in bulk, the Child workspace can use individual jobs to process the parsed data from the Master workspace.
The screenshot below shows the first section of the Master workspace that reads two database tables: Municipalities and Layers. Features from these tables are joined in a one-to-many relationship using a common identifier. An object, or trigger, is then created for each unique Municipality/Layer pair.
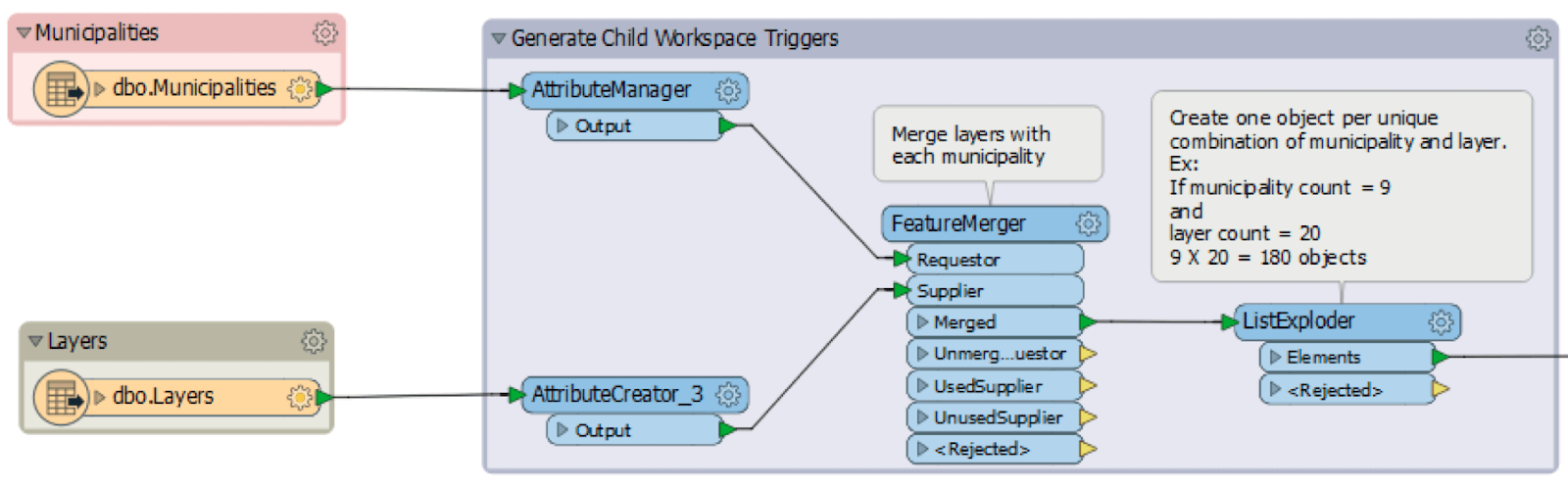
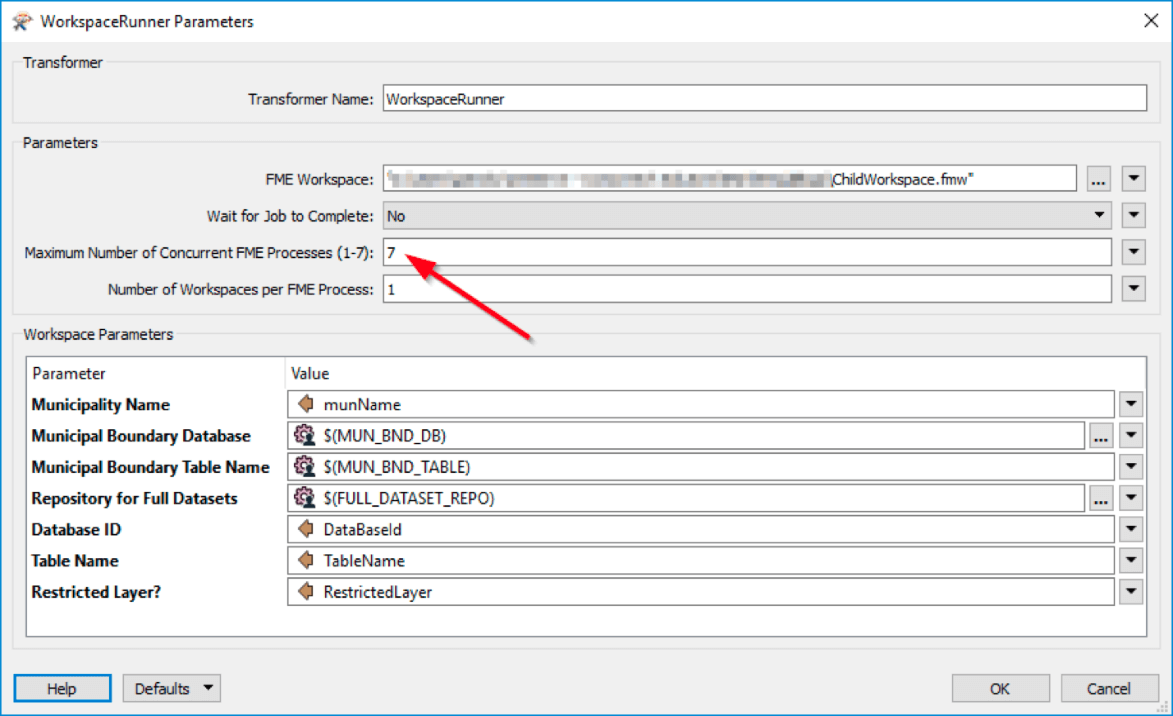
For instance, if you are dealing with 9 Municipalities and 20 Layers, the Master workspace will multiply the two numbers to generate 180 objects, each of which contains a unique set of parameters to trigger the Child workspace. The screenshot below shows the WorkspaceRunner – which is used to call the Child workspace – and its parameter definitions. Some parameters are defined by the Master workspace parameters , while others are defined by the attribute values of each object that was pushed to the Child workspace via the WorkspaceRunner.
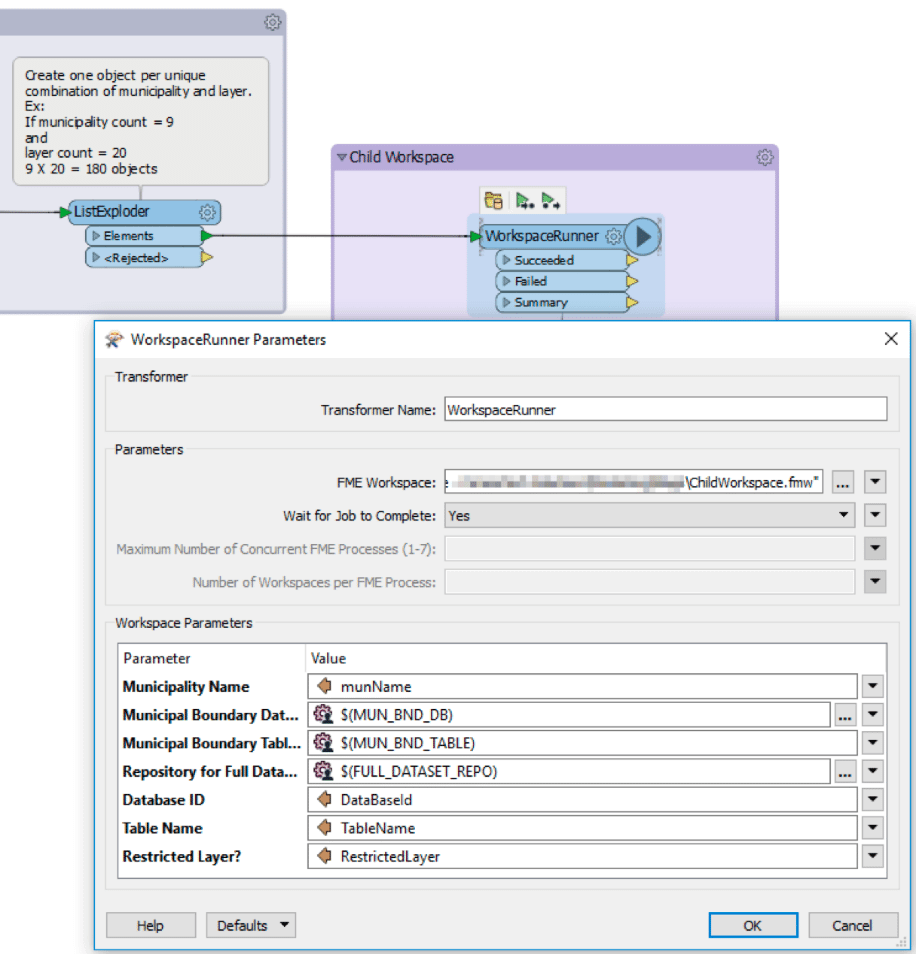
While some workflows may allow you to process all of your data in a single job, there are many benefits to using a workspace chaining approach.
Reduced Memory Usage
The log message below is a symptom of a memory-intensive FME workspace:
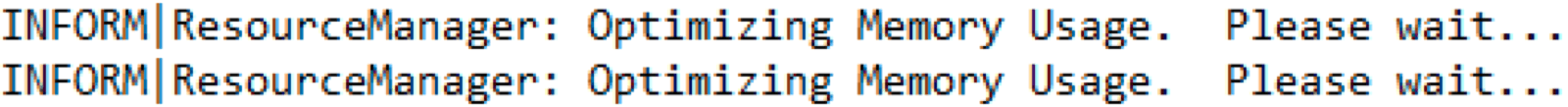
This message often appears when the memory being used by the FME workspace is cached to the point of running out of virtual memory. Some FME transformations will cache memory using blocking transformers – such as FeatureMerger, Aggregator, and Dissolver – or feature type and dataset fan-outs that are likely to result in higher memory usage.
Reducing the number of features that are processed per job will therefore help keep memory usage low, given that cached memory is freed once a workspace completes.
Improved Logging and Error Tracking
Analyzing log files can get tedious, especially when fatal errors occur. Luckily, chaining can provide an antidote, giving you the ability to configure your workspace in a way that generates one log file per Child workspace run.
In the previous scenario, 181 log files can be generated: 1 Master workspace log file and 180 Child workspace log files. The status of Child workspace jobs can be tracked in the Master workspace with the help of the Succeeded and Failed output ports of the WorkspaceRunner.
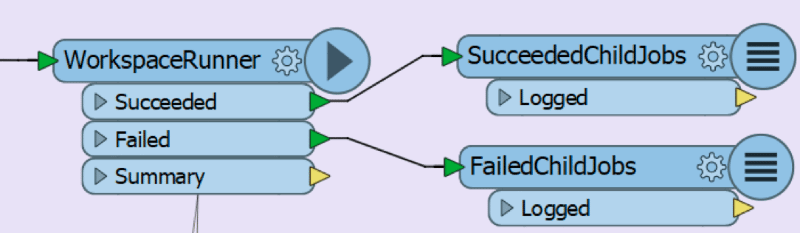
Taking the time to analyze each failed log file makes it easier to identify and isolate unique errors that occur within in a single job. It can also help identify error trends that have affected multiple jobs, such as connectivity issues, incorrect parameter definitions, and more.
Improved performance
Workspace chaining not only reduces memory usage, but it also gives you the ability to run concurrent jobs. Parallel processing can significantly improve your data processing speed, as up to 7 child jobs can run simultaneously. By default, the WorkspaceRunner will run each job sequentially – however, setting the Wait for the Job to Complete parameter to “No” will launch a separate FME process to execute the workspace.
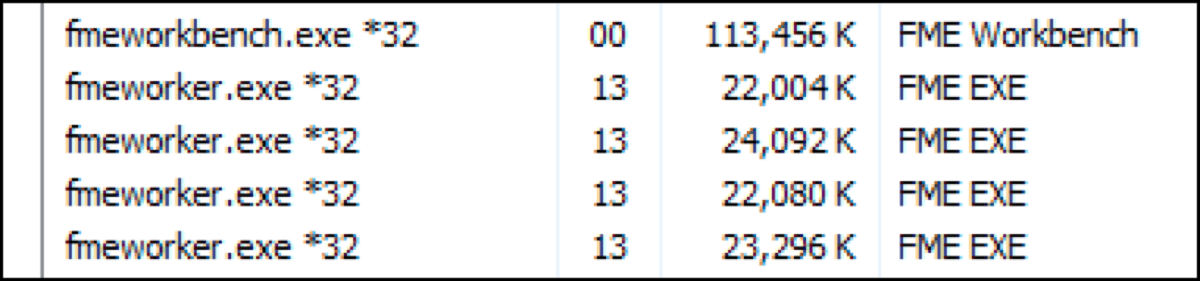
These processes can be found in the task manager as fme.exe or fmeworker.exe instances. Using the previous scenario, the Child workspace has the ability to run up to 7 concurrent instances until all 180 processes are complete, which would take significantly less time than waiting for each individual job to complete before triggering a new one.
Need a hand? For all of your data validation, transformation, conversion, and distribution needs – plus a whole lot more
You may also like :