
FME is known for its ability to convert data between formats as well as applying transformations in an easy and fast way. Most simple conversion and transformation processes run rapidly and before we have time to do anything else, the result is ready. It may happen however that larger transformations, involving 10 000+ features or 100 000+ features take longer to run. Depending on the length of the process and the urgency of the result, it may be worth to investigate on how to make the workspace more efficient.
As a rule of thumb, we try to make use of FME’s strengths to make the process as efficient and as fast as possible to save time and machine memory. This requires in deeper understanding of FME and the way that each Reader, Writer and Transformer work to make most out of them. It also requires time and effort to review the workspace and apply the right transformations at the right moment. If your workspaces run under a few seconds or a few minutes, the time and memory saved might not be worth the effort of reviewing. However, if a workspace takes several minutes and/or hours, it may be worth investigating if the process could be improved to be more efficient.
Here are a few general tips and tricks to make your workspaces more efficient.
1. Profit from “SELECT” and “WHERE” statements with Databases Readers
Databases formats have a parameter to apply a “SELECT” and “WHERE” statements. If you or a colleague have some knowledge of SQL language, you can use these parameters to pre-filter the data that you need to work with.
Sometimes, it is not necessary to read the full table, we only need to get some features from the table. By pre-filtering the data using a “WHERE” clause (or a “SELECT” statement), FME will only bring in the result of these clause into the workspace and prevent the reading of unnecessary features.
Steps:
- Open the feature type parameters and input a WHERE clause

- Click OK.
2. Remove unnecessary attributes
Similarly, to the “WHERE” clause, some attributes may not be required to carry out the process. For tables or layers containing dozens or more of fields, it is rarely the case that we need to extract information from each of these fields, or to use all of them within the translation. Attribute data can weigh heavily in a process, slowing down the workspace (imagine 35 000 features with 40 fields populated for each of them…). By un-checking unnecessary attributes, it “lightens” the data and thus the process.
Steps:
- Open the feature type parameters and go to the “User Attributes” tab
- Uncheck unnecessary attribute
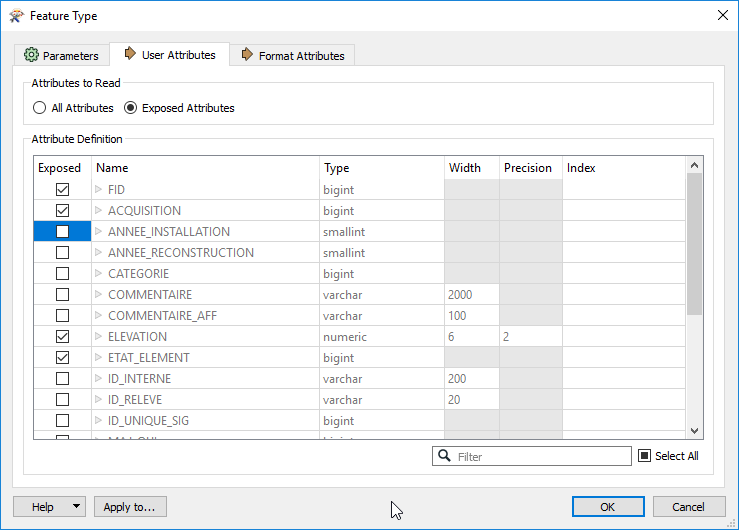
- Click OK
- If the data is read at a later moment in the process, you can also use the AttributeRemover or AttributeKeeper transformers to remove unnecessary attributes.
3. Re-arrange Reader and Writer order
It is possible to re-order Readers and Writers in the navigator window to force the reading and writing order of the datasets. Use this feature to start writing larger datasets first. If you have 2 writers, one writing 500 features and the other one writing 2 000 000 features, get the second writer started first. This will reduce the overall time of the workspace.
Steps:
- Simply perform a “click and drag” on the reader/writer you wish to re-order. The order used if from top to bottom.
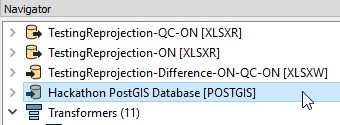
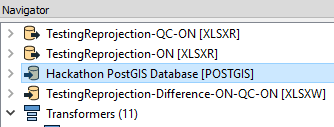
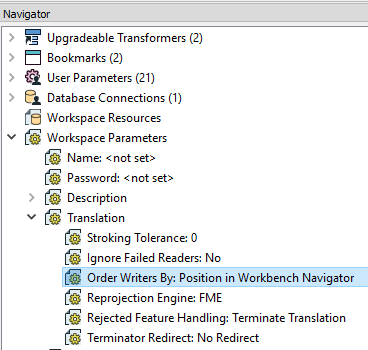
- Then, make sure to set the “Order Writers By:” workspace parameter to “Position in Workbench Navigator”
4. Remove Geometry from features
On the same idea as removing unnecessary attribute information, carrying unnecessary geometry data can slow down a workspace. You can think of a process working only with attribute information as a type of process that doesn’t require the geometry of the features throughout workspace. Complex geometries with a lot of vertices would be good candidates for this case, or any large dataset with geometries.
The GeometryRemover transformer will remove all geometry from the data, keeping only attribute values. However, there is another approach if the geometry must be kept. It is possible to replace the geometry that has been removed from the features by using the GeometryReplacer transformer. It is however necessary to save the geometry information as an attribute on the feature first. This is done by using the GeometryExtractor transformer.
Steps:
- Use a GeometryExtractor to save the geometry as an attribute on the feature. By default, it will create an attribute called “_geometry”.
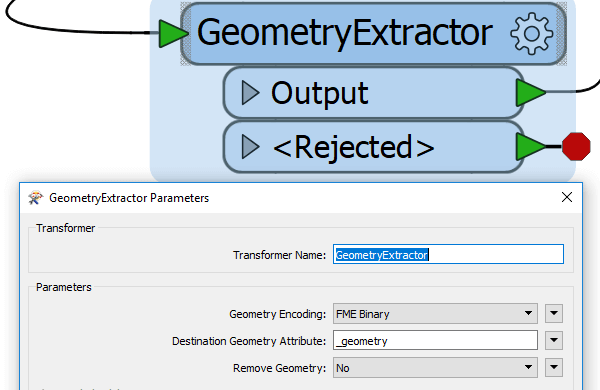
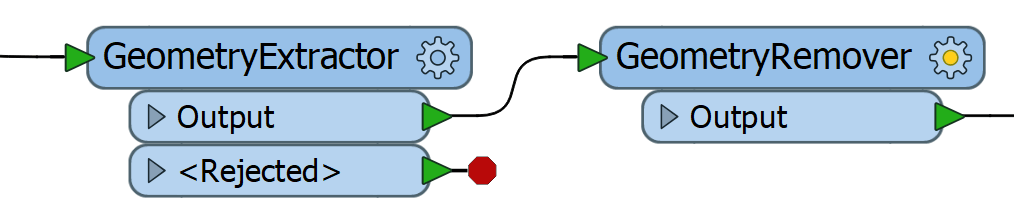
- Then add a GeometryRemover to remove the geometry.
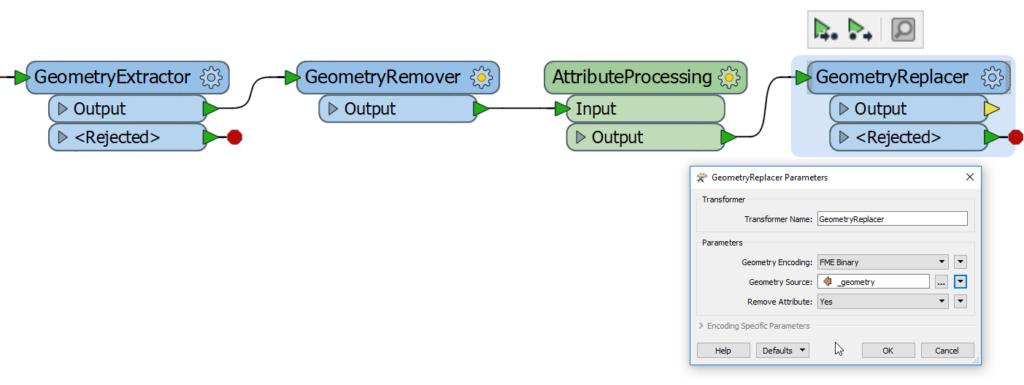
- Continue with the work on attributes (hereby represented with a custom transformer “AttributeProcessing”).

- After the processing of attributes, restore the geometry using the GeometryReplacer. In the parameters, choose Geometry Source parameter as “_geometry” or the name of the geometry attribute created in the first step.

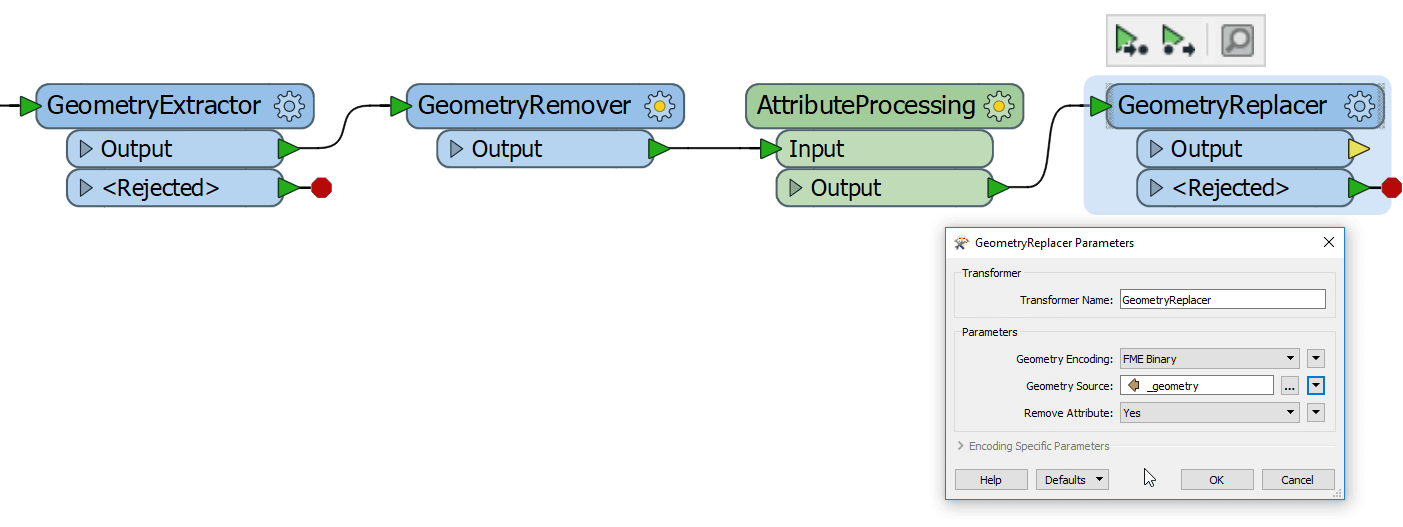
There are of course many other tricks to be more efficient in your workspace processing. Some of them are targeting other specific problems or are useful in different scenarios. But these tips are simple to apply and can bring interesting gains in terms of faster processing time and put less a burden on the system resources.
Do you want to make your FME Workspaces faster? We are champions in this area!