
Data reading is a crucial step in every workspace, since much of a workspace’s success hinges on adequately reading and obtaining information. Efficient data reading also means you don’t have to perform as many manipulations using your workspace’s transformers while making the process lighter and faster.
Here are some tips for better managing the Readers in your FME workspaces.
Change the order of the Readers and Writers in the Navigator
The FME Workbench Navigator lets you drag and drop to reorder your Readers and Writers. This window allows you to force your workspace to read and write specific datasets first.
Filter data at the source to avoid any unnecessary reading
Data processing is at its most efficient when only relevant data is read. By having your workspace read data it ultimately won’t use, you make the process heavier and, consequently, slower. The process takes up more computer resources than you actually need.
We’re not only talking about filtering data early on in the workspace, but also about filtering it directly in the Reader.
FME Readers let you do that with:
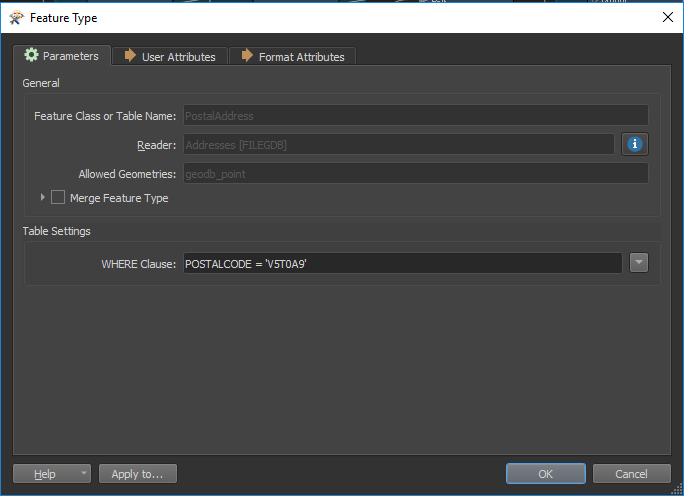
– WHERE Clauses (for database formats). Allows you to specify conditions to filter entities. These conditions are applied directly on the read, which prevents the workspace from reading the entire dataset.
- SQL To Run Before Read. Makes it possible to run an SQL query before reading a table in a database. This feature can come in handy, for example, if you must create a temporary view before the read.

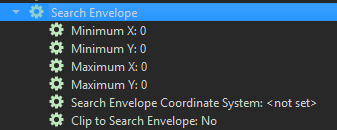
- Search Envelope (XMin, XMax, YMin, YMax). Allows for data to be defined as a geographic area in the Reader, so that only data within this area will be read. Any data outside of those bounds will be disregarded.
Remove irrelevant attributes
In the Reader’s feature types, you can tell the workspace not to read certain data attributes, which makes data lighter and therefore optimizes processing. Most processes won’t require all the attributes available in a dataset, and that where this option comes in handy. To use it, open “Reader Feature Type”, then click on “User Attributes” and uncheck the attributes you won’t be needing.
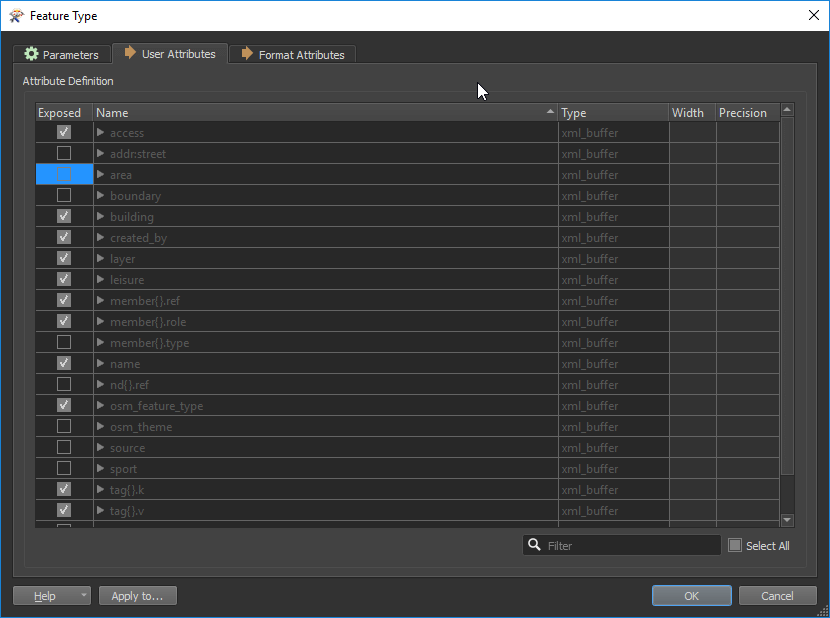
Read data as you go
Sometimes, it can be more efficient start reading data from a specific point in the workspace on. This is helpful when you want to create join relationships with a table from a database or from an external dataset. Certain transformers will let you read this data as a join or query to the dataset, which makes for more efficient processing. Some transformers that can join to external data in this manner include:
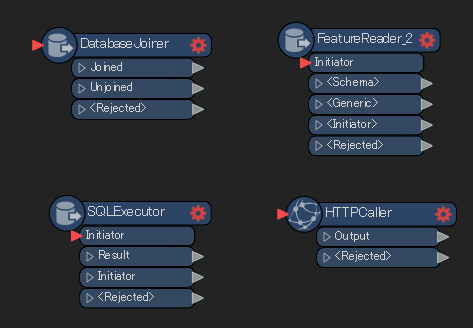
i. DatabaseJoiner
- To create a join relationship with a table from a database
ii. FeatureReader
- To create a join relationship with an external dataset
iii. SQLExecutor
- To launch an SQL query against a database and retrieve information from query results
iv. HTTPCaller
- To retrieve information from a web page or an API
Max Features to Read vs. Max Features to Read Per Feature Type
- Each Reader has a series of parameters called Features to Read. These settings are particularly useful at the development stages, as they make it possible to test your process on a smaller number of features.
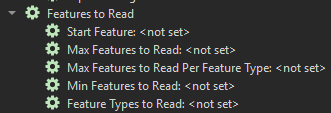
- For instance, if you set the value in Max Features to Read to 100, you’re telling the workspace to only read 100 entities for this specific process.
- It’s important to know that Max Features to Read Per Feature Type only works for the feature types that are explicitly defined in the workspace. It will not be applied when a Merge Feature Type filter is specified or when the Readers are in dynamic mode.
Conclusion
Need a refresher? The most important Reader setting tips to remember are:
- You don’t have to read anything but the data you need (filter directly as you read, exclude all irrelevant attributes), to avoid being bogged down by information that is useless, either for the process at hand or for the final dataset.
- You can change the order of your Readers in the Navigator to tell your workspace which datasets to prioritize.
- Transformers will allow you to create join relationships to read data mid-translation at the most efficient time possible.
- The Max Features to Read setting is a lifesaver at the development stages. It can speed up development by restricting tests to a specific ranged of data.
Would you like more tips and tricks in FME?