
Que vous y soyez préparé ou non, la migration vers les services 9-1-1 de prochaine génération ou Next Generation 9-1-1 (NG911) a commencé aux États-Unis et au Canada. Vous le savez sûrement, les données des systèmes d’information géographique (SIG) joueront un rôle important dans le déploiement et l’analyse des situations. Pour assurer la fluidité des échanges entre les systèmes, la NENA (National Emergency Number Association), qui travaille sur les services 9-1-1 de prochaine génération depuis déjà plusieurs années, a proposé un modèle qui servira de norme pour les données SIG utilisées par les intervenants.
Modèle de données SIG des services NG911
Le modèle de données est une liste de couches (ou tables) qui sont requises, fortement recommandées ou recommandées. Pour chacune de ces couches, un ensemble d’attributs obligatoires, conditionnels et optionnels est établi, ainsi que le type de données attendu pour chaque attribut. L’objectif est de faciliter l’accès aux renseignements requis en plus de réduire le risque ou les problèmes liés à l’adaptation des données SIG de chaque municipalité aux différents utilisateurs.
Voici quelques exemples de couches requises :
- Lignes médianes des routes
- Points d’adresse des emplacements et structures
- Limites des centres téléphoniques de sécurité publique
- Etc.
À quoi peut servir FME?
À beaucoup de choses, bien sûr! Vous le savez, FME accepte facilement les noms d’attributs, les valeurs, les configurations et les entités géospatiales. Pour les besoins de l’article, les exemples s’appliqueront à trois éléments qui vous aideront à préparer et à valider vos données SIG pour le respect des normes de NG911 :
- Concordance des attributs
- Validation des données
- Validation spatiale
Et le meilleur dans tout ça, c’est qu’une fois que les tests de validation sont configurés dans un ou plusieurs workspaces, vous pourrez les exécuter plusieurs fois pour évaluer la qualité de vos données, sans avoir à les recréer chaque fois!
Concordance des attributs
La concordance des attributs consiste à renommer les attributs de votre ensemble de données actuel pour qu’ils correspondent aux noms attendus par la norme de la NENA. La plupart des champs requis doivent contenir un renseignement précis, et c’est pourquoi une concordance 1:1 suffira pour beaucoup d’entre eux. Plusieurs transformers FME pourront vous aider, comme AttributeRenamer, AttributeManager et SchemaMapper.
Ci-dessous, vous voyez comment AttributeManager renomme certains attributs source pour assurer le respect de la norme NENA.
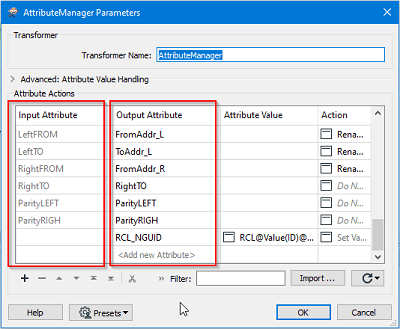
L’attribut RCL_NGUID représente l’identifiant unique de chaque ligne médiane selon le standard NENA. Comme cet attribut n’existe pas dans l’ensemble de données, il est créé par la concaténation de différents renseignements sous la section de la valeur de l’attribut (« Attribute Value ») du transformer.
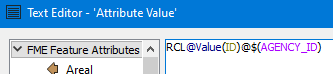
Dans cet exemple, sont enchaînés la constante « RCL », l’attribut d’identifiant de l’ensemble de données (« @Value(ID) »), la constante « @ » et un paramètre publié (« $(AGENCY_ID) ») permettant à l’utilisateur d’entrer l’identifiant de l’organisme à l’exécution. Le résultat ressemblera donc à ceci :
RLC1182039455@cityname.on.ca
Le transformer SchemaMapper fonctionne différemment, car il renomme les attributs selon un document ou un tableau externe contenant un schéma de concordance. Par exemple, voici une capture d’un document de concordance en format Excel qui décrit le processus de renommage requis.
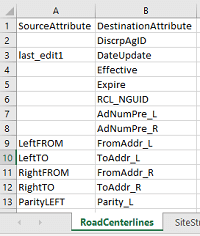
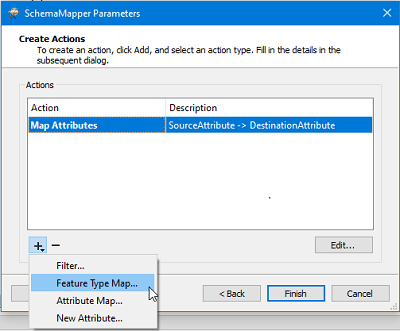
SchemaMapper utilise ce fichier pour effectuer le renommage. Le transformer peut aussi faire d’autres opérations, comme avec la fonction de concordance du type « Feature Type Mapping », qui renomme le type d’attribut de l’entité.
Validation des données
Une fois les attributs bien mappés selon la norme de données, on peut aussi vérifier le type de données attendu, par exemple des caractères ASCII imprimables (« P »), une date et une heure (« D ») ou un nombre entier (« N »). D’autres types sont indiqués dans le document officiel du modèle de données SIG de la NENA.
Pour la vérification de ces caractéristiques, AttributeValidator et d’autres transformers de test sont vos meilleurs outils.
AttributeValidator permet d’effectuer différents tests couvrant la majorité des éléments d’un attribut qui peuvent être vérifiés, par exemple :
- le type (« Type »);
- la capacité d’encodage (« Encodable In »);
- s’il n’est pas nul (« Not Null »);
- s’il a une valeur (« Has a Value »);
- s’il contient une expression rationnelle (« Contains Regex »);
- etc.
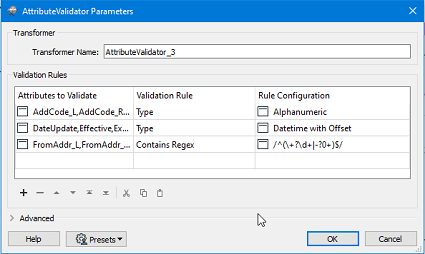
Comme vous le voyez ci-dessus, plusieurs attributs de différents types de données peuvent être mis à l’essai avec AttributeValidator. Le résultat sera une réponse positive ou négative (« Passed » ou « Failed »), comme pour le transformer de test. Si une entité échoue plusieurs tests, cette information sera stockée dans une liste d’attributs (« fme_validation_message_list ») que l’on peut voir dans Data Inspector, dans la fenêtre « Feature Information » :
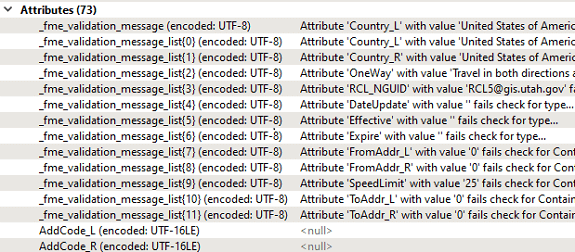
Ensuite, on travaille avec la liste pour extraire les messages de validation séparément, ce qui demande une bonne connaissance du fonctionnement des listes d’attributs dans FME.
Une approche plus simple consiste à utiliser des transformers de test. Il faudra en utiliser plusieurs pour atteindre l’objectif de validation, mais chaque test est contrôlé par un ensemble distinct de transformers, ce qui permet une approche personnalisée. Par exemple, la séquence suivante teste l’attribut « St_Name » pour vérifier s’il contient une valeur; si ce n’est pas le cas, l’attribut « Issue » est créé et reçoit une valeur personnalisée qui sert de message d’erreur.
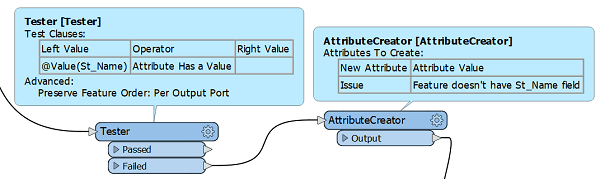
Ce processus offre donc plus de flexibilité, mais requiert des tests précis personnalisés pour la vérification de tous les attributs et de toutes leurs caractéristiques. Il faudra donc un plus grand workspace et davantage de manipulations des transformers.
Validation spatiale
La validation spatiale pourrait être une classe à part entière, car elle nécessite une vérification en fonction de règles bien précises. Sans trop aller dans le détail, voici une liste de transformers utiles et ce à quoi ils peuvent vous servir pour la validation d’entités géospatiales.
| Transformer | Fonction |
|
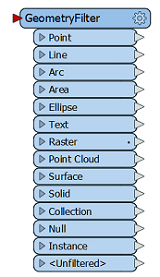
GeometryFilter
|
Vérifie le type de configuration. Retourne un port de sortie pour chaque type de configuration sélectionné et reconnu par FME (point, ligne, polygone/aire, surface, raster, etc.). |
|
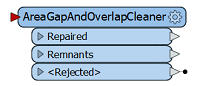
AreaGapAndOverlapCleaner
|
Répare la topologie en corrigeant les interstices et les chevauchements des aires adjacentes. |
|
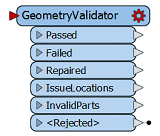
GeometryValidator
|
Vérifie l’intégrité géométrique des entités traitées (p. ex. : polygone se croisant lui-même) et tente de les réparer si possible. |
|
Intersector
|
Ajoute des nœuds lorsque des lignes ou des polygones se croisent. |

FME offre de nombreux outils qui peuvent aider les organisations à préparer leurs données SIG pour les services NG911.
Le logiciel a de multiples fonctions, comme le mappage des attributs, la validation des données et la validation spatiale. Oui, il faudra faire quelques efforts pour mettre sur pied les tests de vérification de la qualité des données, mais il y a une bonne nouvelle : une fois le processus établi, vous pouvez le réutiliser autant de fois que vous voulez de façon itérative pour nettoyer les données. Encore mieux : FME est doté d’outils vous permettant de produire de très beaux rapports, dans n’importe quel format qu’il peut gérer!
Besoin d’un coup de main pour vous préparer à la nouvelle norme de services 911?